Gestion de conflit d’édition
Une grande amélioration qu’amène SPIP 2.0 est la gestion de conflits lors de la rédaction d’un même article (ou autre objet d’édition de SPIP) par deux personnes différentes. Si A et B modifient un article X, et que A valide en premier, ses modifications sont effectuées. Si B valide ensuite, seules les champs que n’a pas modifié A sont enregistrés, et un message apparaît pour les autres champs qui affiche les deux versions et propose à B de corriger le conflit.
Tris des pétitions
Dans le domaine des pétitions, qu’il est possible d’activer depuis l’espace privé d’un article, des petites nouveautés apparaissent : un critère {petition} appliqué à une boucle ARTICLES permet de selectionner les articles ayant une pétition. On peut aussi proposer uniquement les pétitions qui contiennent un texte de description particulier. Ici, toutes les pétitions qui contiennent soutien dans le descriptif : {petition==soutien}
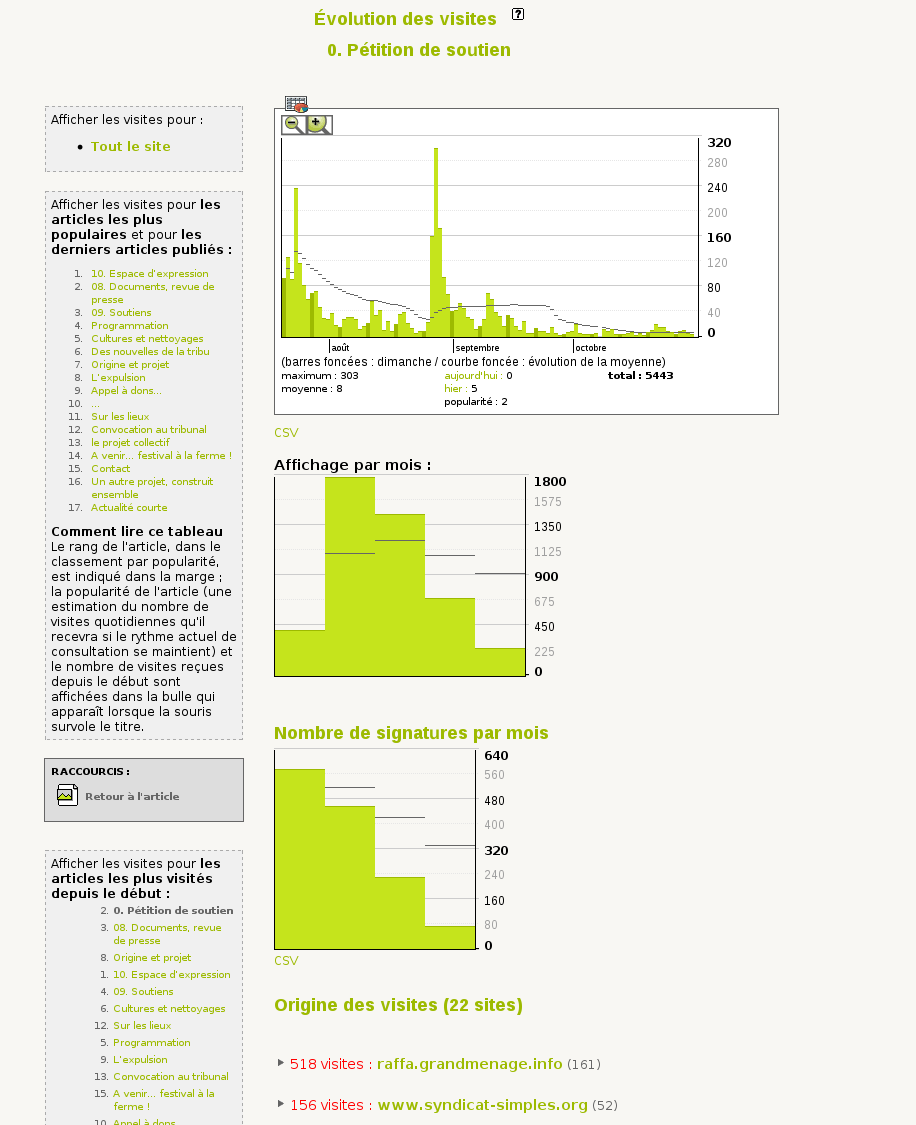
Dans les statistiques du site, un nouveau graphique apparait sur un article ayant une pétition : le nombre de signatures par mois.
Des API SQL...
Une grosse partie du travail effectué sur SPIP 2.0 est invisible au premier abord, et concerne le code de SPIP lui même. Les requêtes SQL d’une part ont été sensiblement optimisées, et d’autre part, celles produites par le compilateur de squelettes génèrent aussi un code assez optimal. Le fait de pouvoir interroger PostgreSQL ou SQLite en plus de MySQL a permis de définir des fonctions spécifiques d’interactions avec la base de données. Ces fonctions sql_* s’inspirent de la logique de la syntaxe SQL tout en permettant d’être assez génériques pour s’adapter à d’autres types de serveurs de données.
et points d’entrées stabilisés
L’aventure des pipelines (points d’entrées) continue. La plupart des actions de SPIP peuvent être complémentées ou modifiées sans toucher le code source du logiciel, simplement en indiquant dans son fichier mes_options.php ou dans les fichiers de plugin plugin.xml qu’un pipeline est utilisé.
Toutes les fonctions de modification de contenu des objets SPIP passent maintenant par les pipelines pre_edition et post_edition permettant de modifier l’enregistrement. Tous les formulaires CVT ont aussi 3 pipelines formulaire_charger, formulaire_verifier, formulaire_traiter pour créer des actions supplémentaires. Un autre nouveau pipeline peut être très pratique : recuperer_fond appelé juste après la compilation d’un squelette et permettant de lui ajouter du contenu.
Voici 3 exemples de plus en plus complexes :
- Au chargement d’un formulaire "Ecrire à un auteur", ajouter l’email de l’expediteur si celui ci est connu dans le champ prévu.
- Ajouter une liste de documents après le formulaire "ajouter un document" (plugin ajaxforms) qui se rechargera en ajax en même temps que le formulaire.
- Enfin, un exemple plus complexe : au moment de publier un article, d’un secteur particulier (8 ici pour simplifier), fixer la date de publication à j+1 du dernier article publié dans le secteur si sa date est supérieure à aujourd’hui, sinon fixer la date à aujourd’hui.
Créer ses propres pipelines
Les plugins de SPIP pouvaient créer leurs pipelines en le déclarant dans le fichier d’options du plugin. Les pipelines étaient uniquement pour PHP. Un squelette peut maintenant définir ses propres pipelines avec la balise #PIPELINE{nom} de sorte que des plugins peuvent ajouter du contenu à certains endroits prévus par un squelette.
Pour un exemple, voici un menu qui s’agrandit lorsque des plugins se déclarent dedans (voir aussi le plugin Boussole qui utilise #PIPELINE{boussole} )
- Un squelette ecrit
[(#PIPELINE{explos_menu,#ARRAY}|en_liste_svp)] - Des plugins ajoutent des elements au tableau comme ceci (en déclarant le pipeline "explos_menu" dans le fichier plugin.xml) :
- La fonction
en_liste_svp()peut être de la sorte :
- on pourrait tout aussi bien éviter l’utilisation de cette fonction en utilisant le plugin SPIP-Bonux qui permet de boucler des tableaux. On obtiendrait ainsi :
Joindre les deux boucles
Si vous souhaitez créer un objet (appelons le Wistiti) qui pourrait être lié aux articles, aux rubriques ou aux mots clés (pourquoi pas hein ?!), SPIP propose maintenant un moyen simple de s’en sortir.
Il suffit de créer une table spip_wistitis ayant un id_wistiti comme clé primaire et d’autres champs. Une table de liaison avec les autres objets de SPIP sera nommée spip_wistitis_liens et se composera d’au minimum 3 champs : id_wistiti, objet, id_objet.
Pour déclarer et installer les tables, il faudra définir où se situe le fichier d’installation, ainsi que signaler l’utilisation de certains pipelines dans le fichier plugin.xml :
Commençons par regarder le fichier base/wistitis.php qui permet de définir la table à créer et les jointures à appliquer :
Les tables étant alors déclarées, il est possible d’ajouter les fonctions d’installation et de suppression des tables du plugin. Pour cela, il faut créer les 2 fonctions correspondantes dans le fichier d’installation :
Vous aurez besoin de créer 2 formulaires CVT : un pour editer un Wistiti, l’autre pour lier un wistiti à un objet. Je ne détaille pas cela, seulement je vais présenter une fonction de SPIP bien pratique pour la modification de contenu.
Lorsque vous créez (via le formulaire) un nouveau Wistiti, vous allez effectuer une insertion dans la base de donnée en récupérant le nouvel identifiant créé, par exemple, dans la partie traiter() du formulaire CVT vous pouvez tester cela :
Une fois que l’enregistrement est présent, il suffit de récupérer les champs et d’effectuer la modification du contenu en fonction de ce qui a été posté dans le formulaire, grâce à la fonction modifier_contenu() :
Cette fonction a l’avantage d’appeler les pipelines pre_edition et post_edition pour l’appel realisé.
Ce qui est intéressant de noter, c’est qu’une fois les liaisons établies, SPIP sait se débrouiller à joindre les boucles et à traduire automatiquement les critères {id_article=XX} en requete SQL objet='article' AND id_objet=XX lorsque nécessaire.
Ainsi, vous pouvez ecrire :
Mutualiser les ressources
Ce qui peut intéresser les hébergeurs, ou les développeurs qui souhaitent se faciliter la maintenance est la réalisation de mutualisations. Un jeu de fichiers de SPIP peut maintenant servir à faire fonctionner plusieurs sites en SPIP. C’est ce qu’on appelle la mutualisation du noyau de SPIP. Il est par ailleurs possible de mutualiser d’autres éléments de SPIP, comme des plugins ou des squelettes.
Pour cela, une fonction spécifique (spip_initialisation) permet de démarrer SPIP avec un certain nombre de paramètres définissant le lieu des fichiers indispensables au site à charger. Ces paramètres souvent calculés à partir de l’URL de la page appelée permettent de charger un site ou un autre en fonction de l’URL appelée. Le serveur php peut alors bénéficier d’un meilleur cache des fichiers (puisque un même fichier est appelé pour plusieurs sites) et le webmaster bénéficie d’une maintenance plus facile : mettre à jour tous les sites revient à mettre à jour uniquement le noyau de SPIP.
Un plugin mutualisation facile permet de faciliter la création de tels espaces.
Compléments alimentaires...
Il y a forcément des oublis... Et un manque de temps pour tout écrire !
L’article sera complété au fur et à mesure...
Sur ce, bon soleil à tous.